
Welcome to a new generation of speech recognition.
By voice-enabling everyone, on virtually anything -- web & mobile apps, devices, vehicles, industrial systems -- SensibleSpeech augments products, empowers users and delivers immediate ROI.
In software API or server appliance version, SensibleSpeech brings plug & play voice to any application and runs on any infrastructure, including your own exclusively.
In middleware version, SensibleSpeech brings voice to any device or equipment, thereby freeing the hands and moves of operators. It works with or *without* network connection, making it ideal for military and medical requirements.
Because SensibleSpeech is GAFAM-free, it can be trained on specific business vocabularies, keeps productions costs under control, secures data end-to-end and complies with GDPR and all other privacy regulations.
The time for voice is now.
Discover why adopting SensibleSpeech is the most sensible decision you can make today...
SensibleSpeech's critical features
-
Functional
- ●Voice-enables any application or device
- ●Works with or without network connection
- ●Available with generic or industry-specific models (e.g. Medical)
- ●100% adaptable to corporate or industry vocabularies
- ●Live / offline / batch transcriptions by drag & drop
- ●Downloadable audio and texts transcripts, from live audio or media files
- ●Directly pluggable to vertical-specific NLUs, including LEXISTEMS'
- ●100% customizable in the functional and lexical areas.
-
Technical
- ●Available as a software, middleware or hardware solution (device or API server appliance)
- ●Available in 3 modes: remote API, partially or fully embedded (cloud / edge)
- ●API mode installable on any infrastructure, including 100% on-premises
- ●Embedded mode compatible with the most constrained hardware platforms and equipments
- ●Comes with optimized, fully customizable frontend user interfaces
- ●Ethical architecture.
-
Eco-responsibility
- ●Eco-responsible from design to production use
-
Availability and support
- ●Available and supported worldwide through the SENSIBLE Alliance.
-
GAFAM-free and therefore
- ●...sensibly cost-effective via subscription or one-off pricings
- ●...fully secured and compliant with all Data and Privacy regulations, end to end.
SensibleSpeech solves vocal pain points
Everyone wants voice in their apps and devices.
SensibleSpeech delivers it today, all inclusive, for a fraction of the costs.

Examples of SensibleSpeech use cases
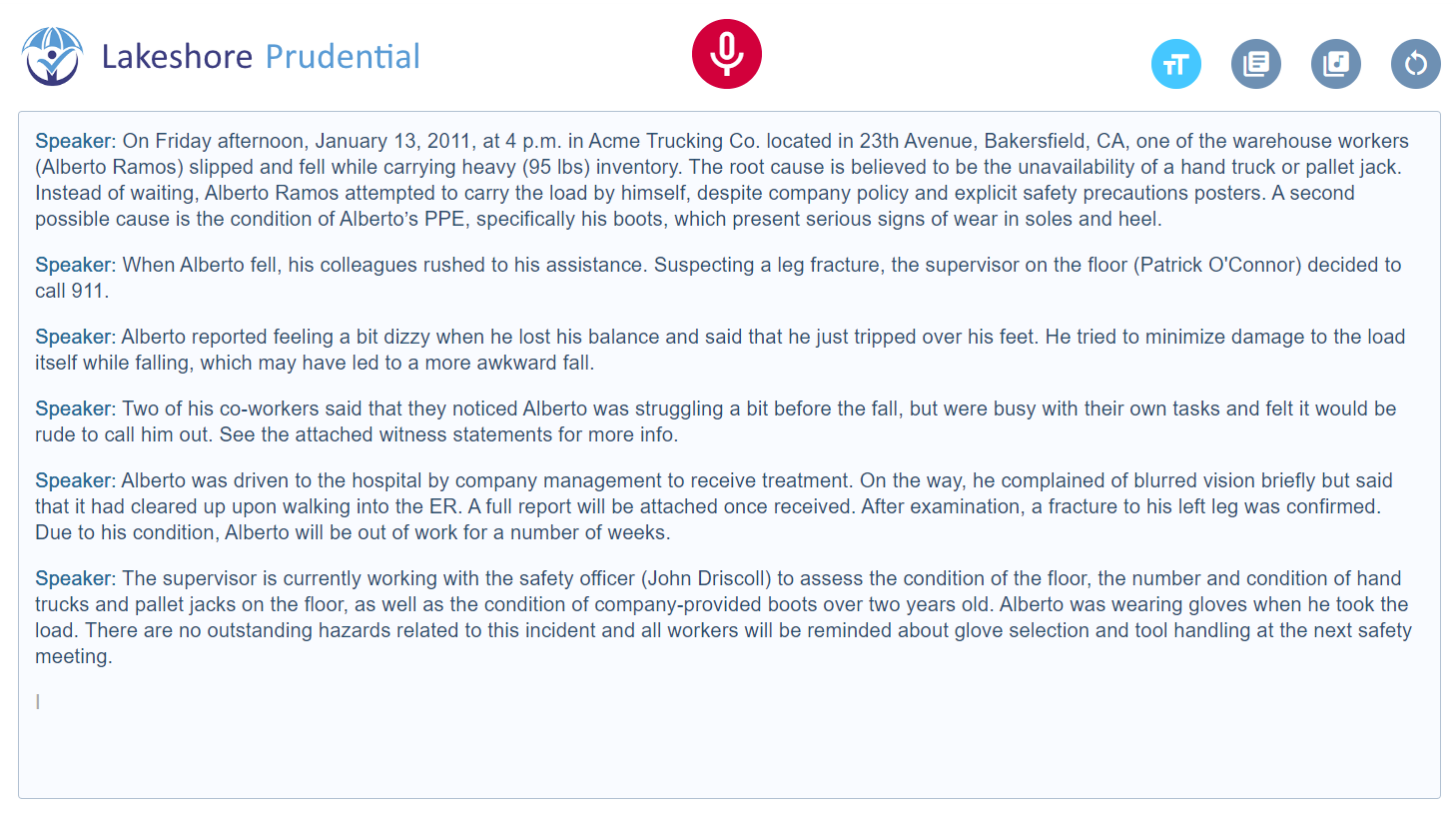
Prudential - Business-oriented record / dictate
Problems solved - This project illustrates how live recording or dictation is one of the most demanding speech recognition applications. As a reminder, recording applies automatic punctuation; in dictation, punctuation is left to the speaker. In both cases, speech recognition must support the infinite variety of human expression, understand business-specific vocabularies and be as resilient as possible to conditions like accents, ambient noise, etc. Designed for recording or dictation in several languages, SensibleSpeech meets these requirements. It is available with general or vertical-specific models (e.g. Medical & life sciences, see the screen capture at the bottom of this page) and can be trained on custom / corporate specificities. With every SensibleSpeech applications, audio recordings + text transcripts are accessible for download for legal and archiving purposes.
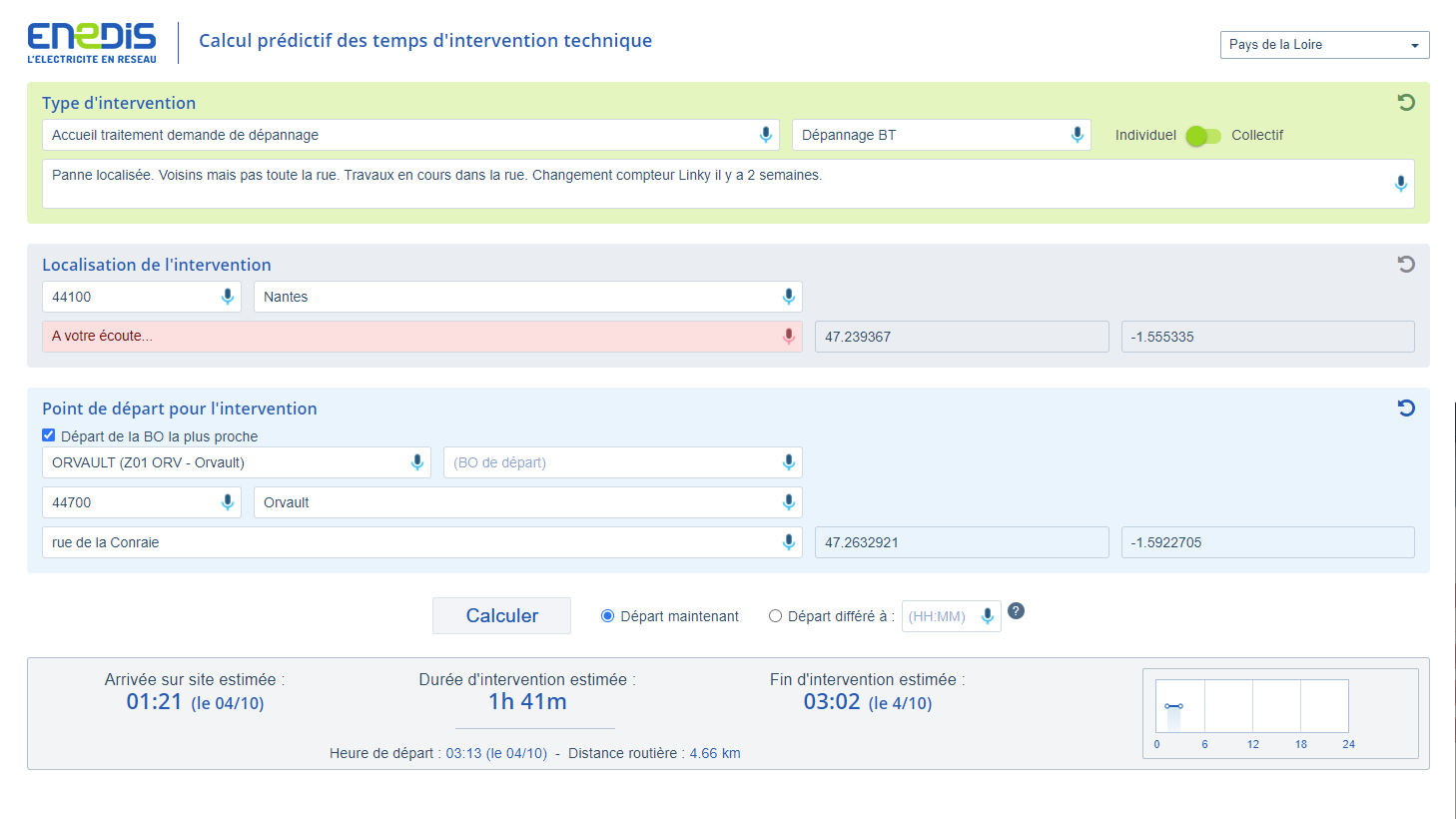
Enedis Cinke - Voice enabling an existing application
Problems solved - This project (already presented with LEXISTEMS SensibleSearch) is a good example of how SensibleSpeech easily augments existing applications. It just took a few lines of frontend code to enable vocal control. In this case, the application has two roles: first, it collects information on power incidents (or other customers requests) and assigns response teams based on location and internal planning. Then, it predicts different timings, including arrival on site and duration of the repair works given the specific incident or request conditions. By voice enabling all input fields, the time to collect information and give customers an estimated repair time is slashed by half. With SensibleSpeech, voice-enablement works on all browser or mobile terminals, giving employees a consistent efficiency regardless of the application's context of use.
Note: this project combines SensibleSpeech and SensibleSearch.
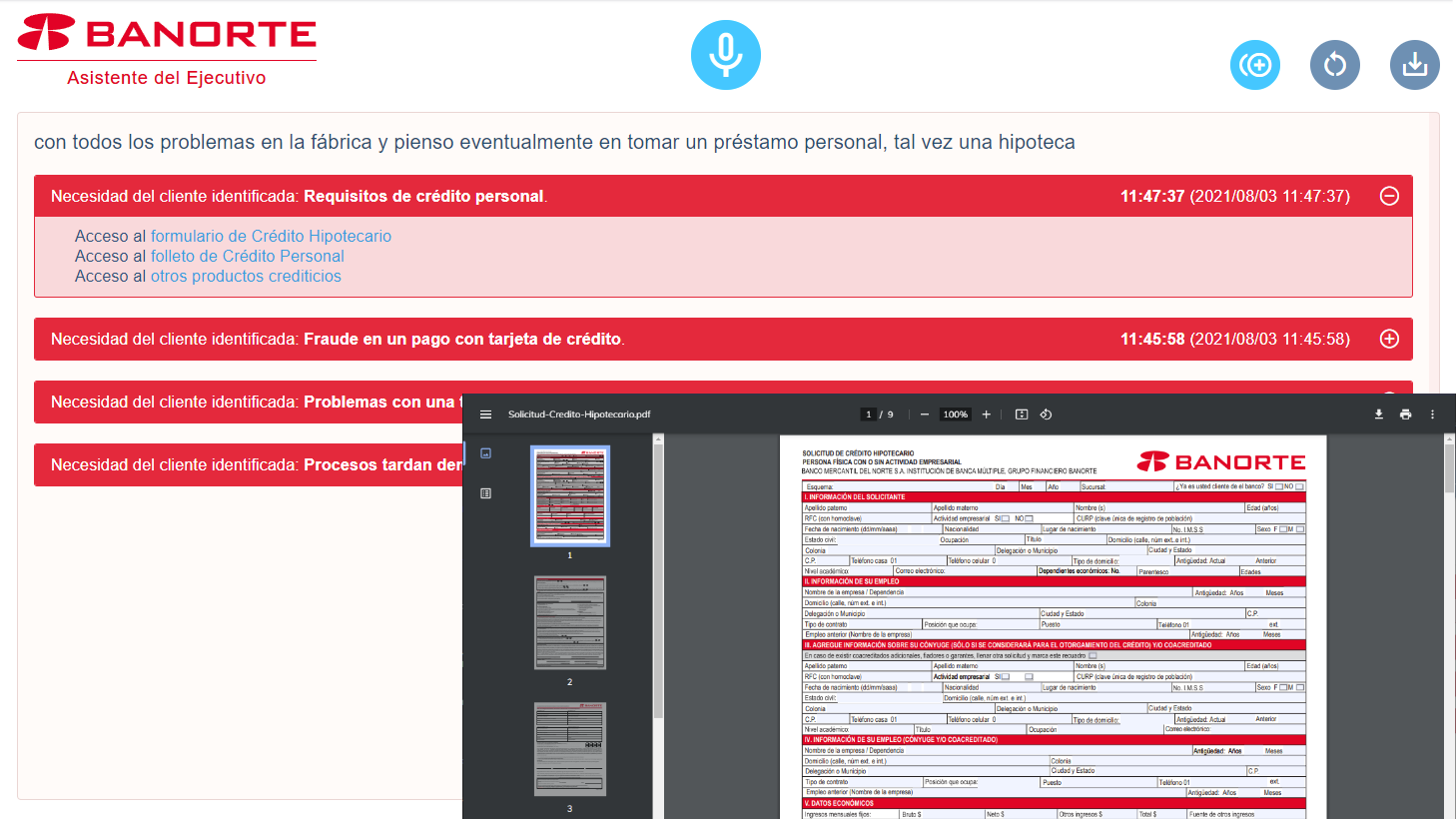
Banorte - A smart bank officer assistant
Problems solved - In this on-going project with Banorte, Mexico's second largest bank, SensibleSpeech is used to listen to conversations between customers and branch officers. Whenever certain predefined topics arise in the conversation, SensibleSpeech records their time and occurrence, and fetches in real time relevant forms, brochures and other customer care documents automatically. The officer can therefore respond immediately to the customer's needs. This provides Banorte's employees with all necessary resources on a potentially infinite range of customer requests, promotes products or services based on seasonal sales strategies and helps Banorte optimize costs on training and internal communication. Conversations and commented transcripts are available for download and other legal requirements. They can be automatically converted into CRM records.
Note: this project combines SensibleSpeech and SensibleSearch.
Your SensibleSpeech ROI
All Speech recognition solutions are not created equal.
Here is why SensibleSpeech is the soundest choice ROI-wise:

speedBenchmarks
WER metrics [1]
| English | French | Spanish | ||||
|---|---|---|---|---|---|---|
| LibriSpeech | Common Voice | Common Voice | MLS | Common Voice | MLS | |
| Amazon Transcribe | 16.21% | 9.55% | 26.56% | 25.48% | 13.65% | 11.96% |
| Google STT | 13.36% | 33.45% | 37.07% | 29.21% | 16.25% | 20.80% |
| IBM Watson | 16.57% | 35.94% | 35.00% | 52.00% | 21.26% | 25.50% |
| Microsoft Azure STT | 11.57% | 7.27% | 12.76% | 49.86% | 7.60% | 30.00% |
| SensibleSpeech | 4.86% | 11.34% | 4.33% | 5.82% | 6.36% | 7.40% |
| English | ||
|---|---|---|
| LibriSpeech | Common Voice | |
| Amazon Transcribe | 16.21% | 9.55% |
| Google STT | 13.36% | 33.45% |
| IBM Watson | 16.57% | 35.94% |
| Microsoft Azure STT | 11.57% | 7.27% |
| SensibleSpeech | 4.86% | 11.34% |
| French | ||
|---|---|---|
| Common Voice | MLS | Amazon Transcribe | 26.56% | 25.48% |
| Google STT | 37.07% | 29.21% |
| IBM Watson | 35.00% | 52.00% |
| Microsoft Azure STT | 12.76% | 49.86% |
| SensibleSpeech | 4.33% | 5.82% |
| Spanish | ||
|---|---|---|
| Common Voice | MLS | |
| Amazon Transcribe | 13.65% | 11.96% |
| Google STT | 16.25% | 20.80% |
| IBM Watson | 21.26% | 25.50% |
| Microsoft Azure STT | 7.60% | 30.00% |
| SensibleSpeech | 6.36% | 7.40% |
WER, or Word Error Rate, is a standard metric for comparing speech recognition systems. It measures the percentage of words left out or misinterpreted during audio recognition.
MER metrics [1]
| English | French | Spanish | ||||
|---|---|---|---|---|---|---|
| LibriSpeech | Common Voice | Common Voice | MLS | Common Voice | MLS | |
| Amazon Transcribe | 15.12% | 8.57% | 24.97% | 24.35% | 12.69% | 11.32% |
| Google STT | 12.87% | 32.3% | 36.40% | 28.71% | 15.76% | 20.13% |
| IBM Watson | 15.55% | 32.77% | 33.01% | 51.20% | 19.98 | 24.83% |
| Microsoft Azure STT | 11.29% | 6.99% | 12.28% | 49.38% | 7.30% | 29.83% |
| SensibleSpeech | 4.68% | 11.29% | 4.29% | 5.79% | 6.18% | 7.20% |
| English | ||
|---|---|---|
| LibriSpeech | Common Voice | |
| Amazon Transcribe | 15.12% | 8.57% |
| Google STT | 12.87% | 32.30% |
| IBM Watson | 15.55% | 32.77% |
| Microsoft Azure STT | 11.29% | 6.99% |
| SensibleSpeech | 4.68% | 11.29% |
| French | ||
|---|---|---|
| Common Voice | MLS | Amazon Transcribe | 24.97% | 24.35% |
| Google STT | 36.40% | 28.71% |
| IBM Watson | 33.01% | 51.20% |
| Microsoft Azure STT | 12.28% | 49.38% |
| SensibleSpeech | 4.29% | 5.79% |
| Spanish | ||
|---|---|---|
| Common Voice | MLS | |
| Amazon Transcribe | 12.69% | 11.32% |
| Google STT | 15.76% | 20.13% |
| IBM Watson | 19.98% | 24.83% |
| Microsoft Azure STT | 7.30% | 29.83% |
| SensibleSpeech | 6.18% | 7.20% |
MER, or Match Error Rate, is the probability of a given match (between speech and recognition) being incorrect.
WIL metrics [1]
| English | French | Spanish | ||||
|---|---|---|---|---|---|---|
| LibriSpeech | Common Voice | Common Voice | MLS | Common Voice | MLS | |
| Amazon Transcribe | 23.71% | 12.59% | 34.59% | 37.07% | 19.03% | 17.85% |
| Google STT | 19.62% | 39.09% | 44.16% | 40.28% | 21.86% | 28.20% |
| IBM Watson | 24.41% | 43.78% | 45.13% | 72.06% | 26.43% | 38.01% |
| Microsoft Azure STT | 15.41% | 10.51% | 18.51% | 55.44% | 10.87% | 33.70% |
| SensibleSpeech | 7.75% | 2.08% | 7.28 | 8.28% | 10.20% | 11.90% |
| English | ||
|---|---|---|
| LibriSpeech | Common Voice | |
| Amazon Transcribe | 23.71% | 12.59% |
| Google STT | 19.62% | 39.09% |
| IBM Watson | 24.41% | 43.78% |
| Microsoft Azure STT | 15.41% | 10.51% |
| SensibleSpeech | 7.75% | 2.08% |
| French | ||
|---|---|---|
| Common Voice | MLS | Amazon Transcribe | 34.59% | 37.07% |
| Google STT | 44.16% | 40.28% |
| IBM Watson | 45.13% | 72.06% |
| Microsoft Azure STT | 18.51% | 55.44% |
| SensibleSpeech | 7.28% | 8.28% |
| Spanish | ||
|---|---|---|
| Common Voice | MLS | |
| Amazon Transcribe | 19.03% | 17.85% |
| Google STT | 21.86% | 28.20% |
| IBM Watson | 26.43% | 38.01% |
| Microsoft Azure STT | 10.87% | 33.70% |
| SensibleSpeech | 10.20% | 11.90% |
WIL, or Word Information Lost, is a probabilistic approximation to the proportion of word information not being preserved during recognition.
Given the specificities of speech recognition, no single metric is enough in itself to define performance. If WER has become the de facto standard, real world uses prove that it is affected by ambiant noise, accents, crosstalk and rare words. MER and WIL have been introduced to compensate for these flaws. In this respect, WIL is a finer-grained measurement of recognition exactness.
It is an industry practice to evaluate speech recognition systems on audio datasets that are themselves standardized and publicly available. Among them, LibriSpeech is the most used worldwide, but it is only available for English. Common Voice and MLS are good substitutes for non-English evaluations.
These scripts are available upon demand.
[1] September 2022 update.
handymanTechnical requirements
verifiedCertifications
Availability - Pricing - Support

Meet SensibleSpeech
Don't miss out on voice.
In a one-to-one session or an interactive video call, see for yourself how SensibleSpeech will benefit your business...