
Welcome to true document summarization. Meaning-based. State-of-the-Art.
SensibleSummaries is very easy to use and appreciate: just select, paste or drop a document, and in 1 click you get it back as a text, PDF or vocal summary.
Available as a software API or plug-and-play server appliance, SensibleSummaries brings summarization to any of your applications and runs on any infrastructure, including your own exclusively.
Because Sensiblesummaries is GAFAM-free, it can be trained on specific documents and vocabularies, keeps costs under control, secures data end-to-end and complies with GDPR and all other privacy regulations.
Business time is money.
Discover why adopting SensibleSummaries is the most sensible decision you can make today...
SensibleSummaries' critical features
-
Functional
- ●Summarizes any text or document
- ●Text, PDF or vocal summaries: 1-click operation
- ●Generative summarization or extractive key points
- ●Results' length and bias adjustable to user or organization preferences
- ●100% adaptable to corporate or industry vocabularies
- ●Full data access control (enterprise directories, user profiles, custom categories)
- ●Directly pluggable to any CMS, search engine or business application.
-
Technical
- ●Available as a software or plug & play hardware solution (API / server appliance)
- ●Installable on any infrastructure, including 100% on-premises
- ●Optimized GPU requirements
- ●Ethical architecture.
-
Eco-responsibility
- ●Eco-responsible from design to production use
- ●Optional carbon metrics returned with all summaries.
-
Availability and support
- ●Available and supported worldwide through the SENSIBLE Alliance.
-
GAFAM-free and therefore
- ●...sensibly cost-effective via subscription or one-off pricings
- ●...fully secured and compliant with all Data Privacy regulations, end-to-end.
SensibleSummaries solves information overload pain points
More and more to know in less and less time...
SensibleSummaries gives you the gist of any text or document -- in your preferred format.

Examples of SensibleSummaries use cases
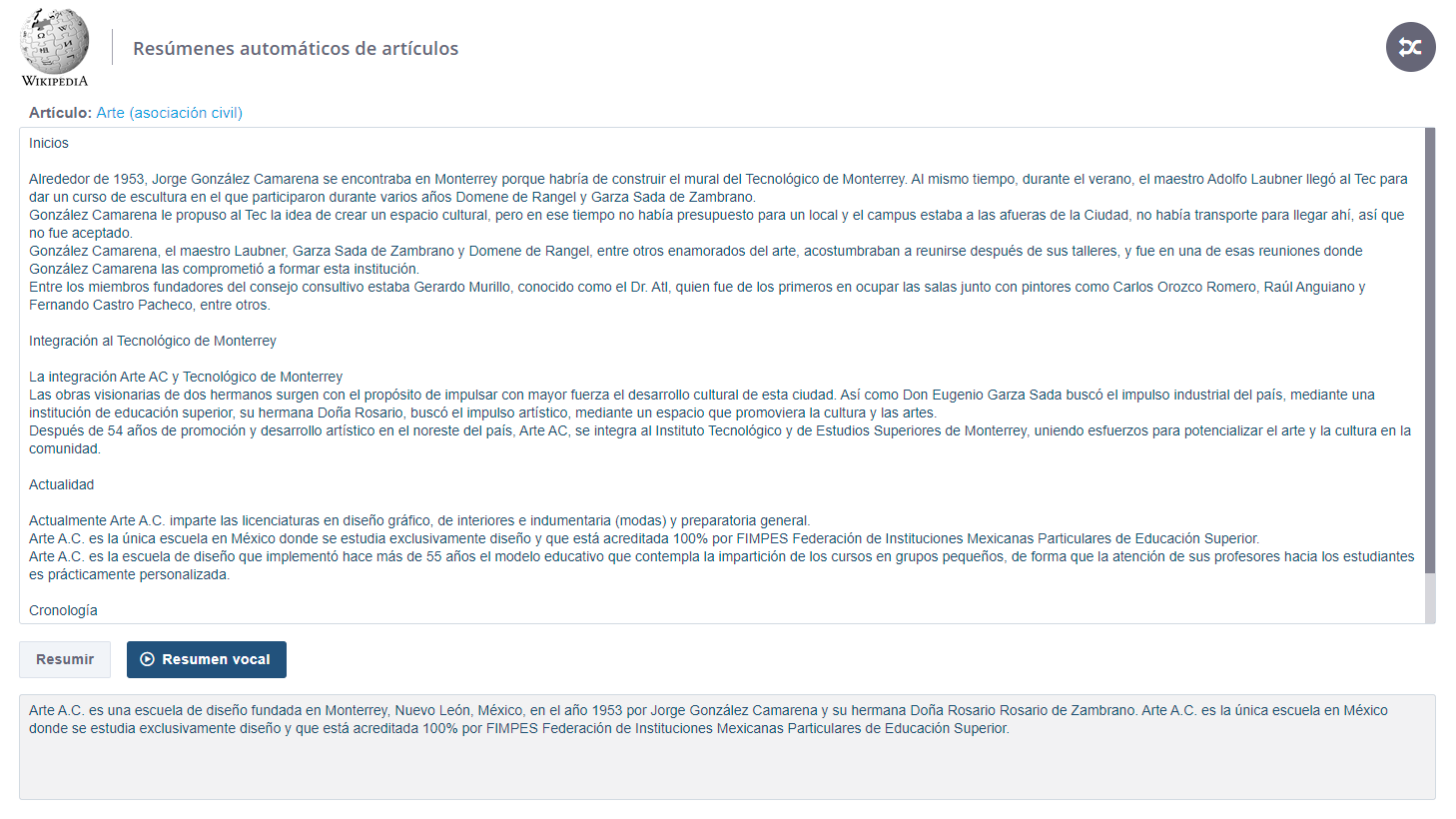
Wikipedia Spanish
Context - Wikipedia is a valuable test case because of its variety in contents and styles, even though a factual bias is encouraged. This bias is precisely one of the main interests here: facts are what most summaries users want, and anyone can appreciate the pertinence of the result from reading the source. We present the Spanish version as Spanish is one of the lesser available language in summarization. French and English versions are available as well.
Documents type - This demo features a selection of articles on many topics - artistic, technical, historical, biographical - and of different lengths. As with other SensibleSummaries demos, the source area also accepts pasted text (any content, from Wikipedia or not).
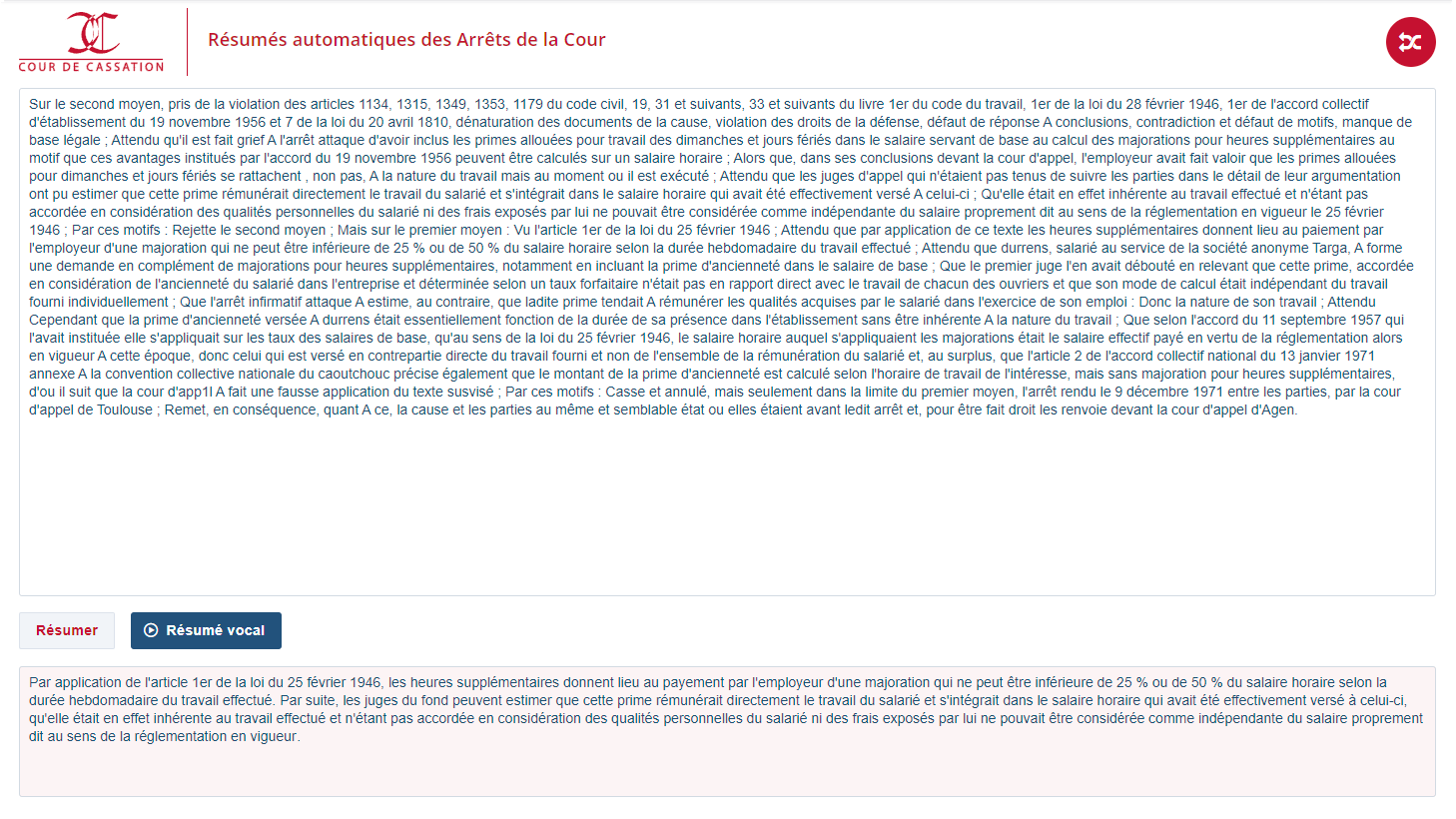
France's supreme Court Decisions
Context - The Cour de Cassation is France's highest jurisdiction in matters of civil and criminal law. Its Decisions are often archived in digital format and that's what made this use case interesting: the many imperfections of the source texts (see the example capture, see the comments below) add a layer of complexity to the specific legal phrasing. References are often implied in reasoning or wording. General and case-specific remarks are of equal importance. Decisions' structures follow quite different received patterns... All these combined result in countless difficulties of understanding and risks of misinterpretation.
Documents type - The Court's Decisions are processed in raw electronic format: blocks of unstructured text (single database string-type records) with often deficient punctuation and casing due to initial OCR ingestion.
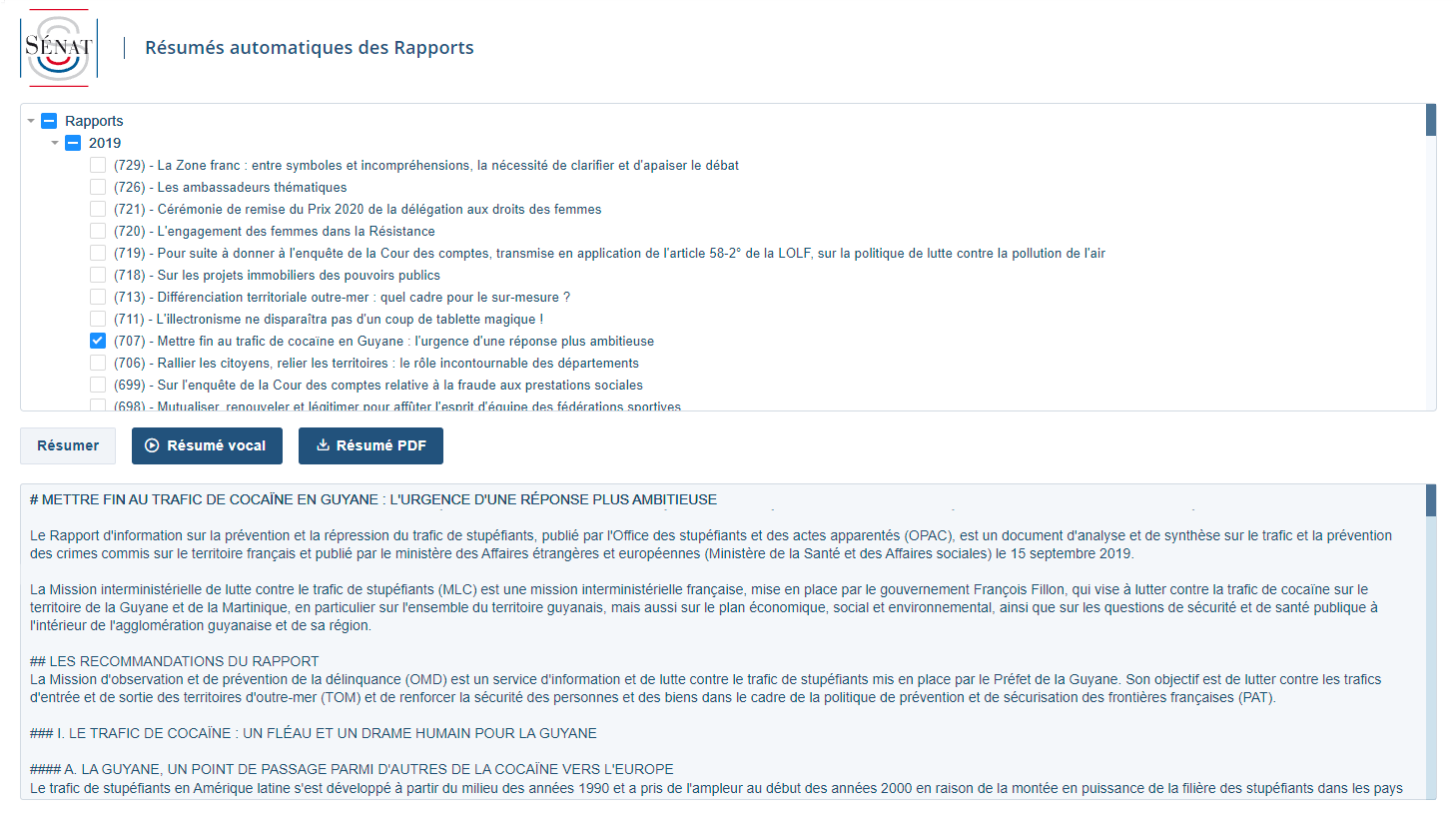
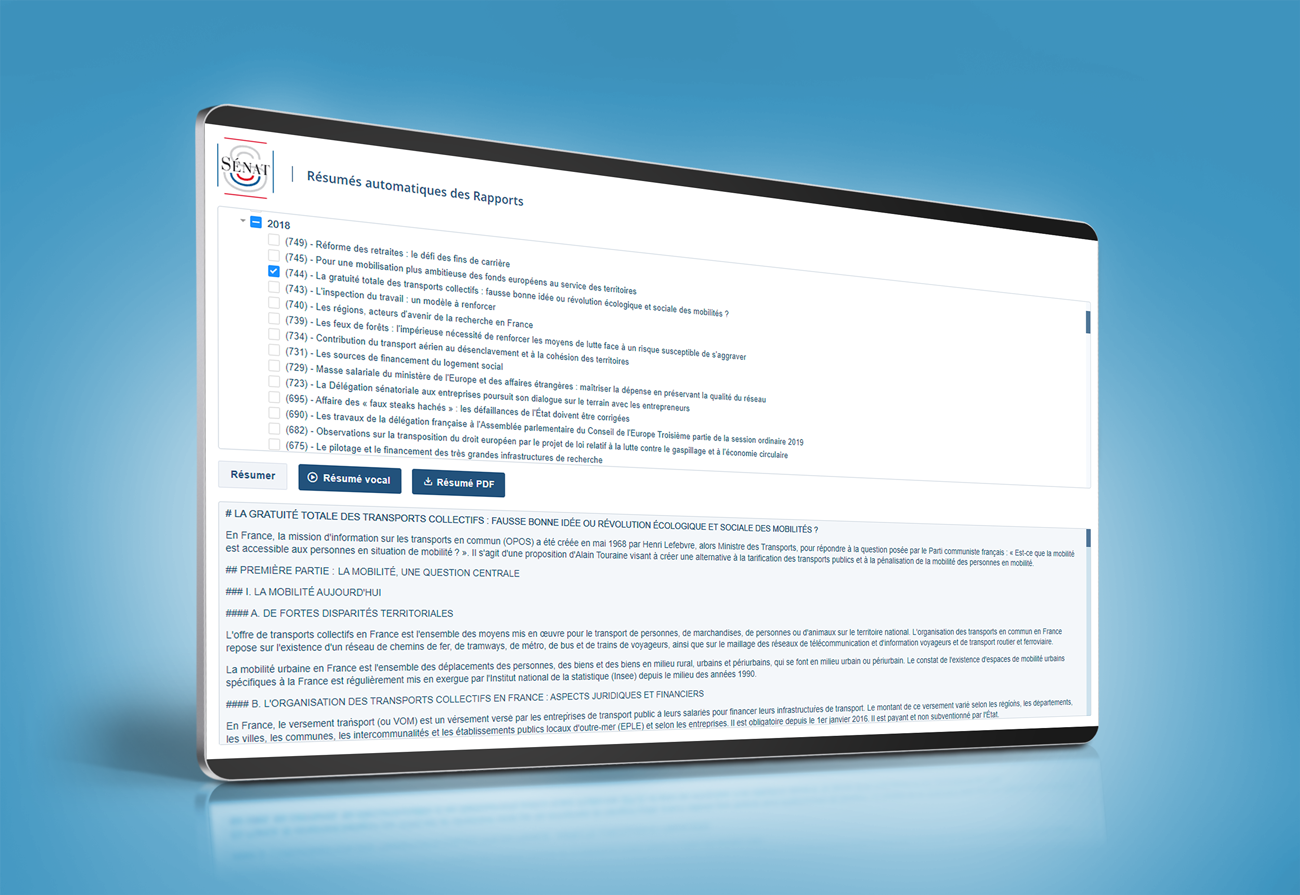
French Senate Reports
Context - France's Senators produce numerous Reports on the country's problems, trends and evolutions. As with every 100+ pages documents, summarization is a huge time saver even though, given the extreme variety of topics and forms in this use case, some Reports summaries are not yet perfect (they're just state-of-the-art). PDF summaries are generated on the backend side and directly readable / downloadable in frontend. When in text only, summaries are delivered in markdown format in order to preserve the documents' initial structure. In either format, they're available in about 30 seconds.
Documents type - In this use case, the Reports are stored in a dedicated repository to which a SensibleSummaries API is connected (contrary to most other use cases presented here, users cannot paste content). The Reports selector adapts to the repository's updates.
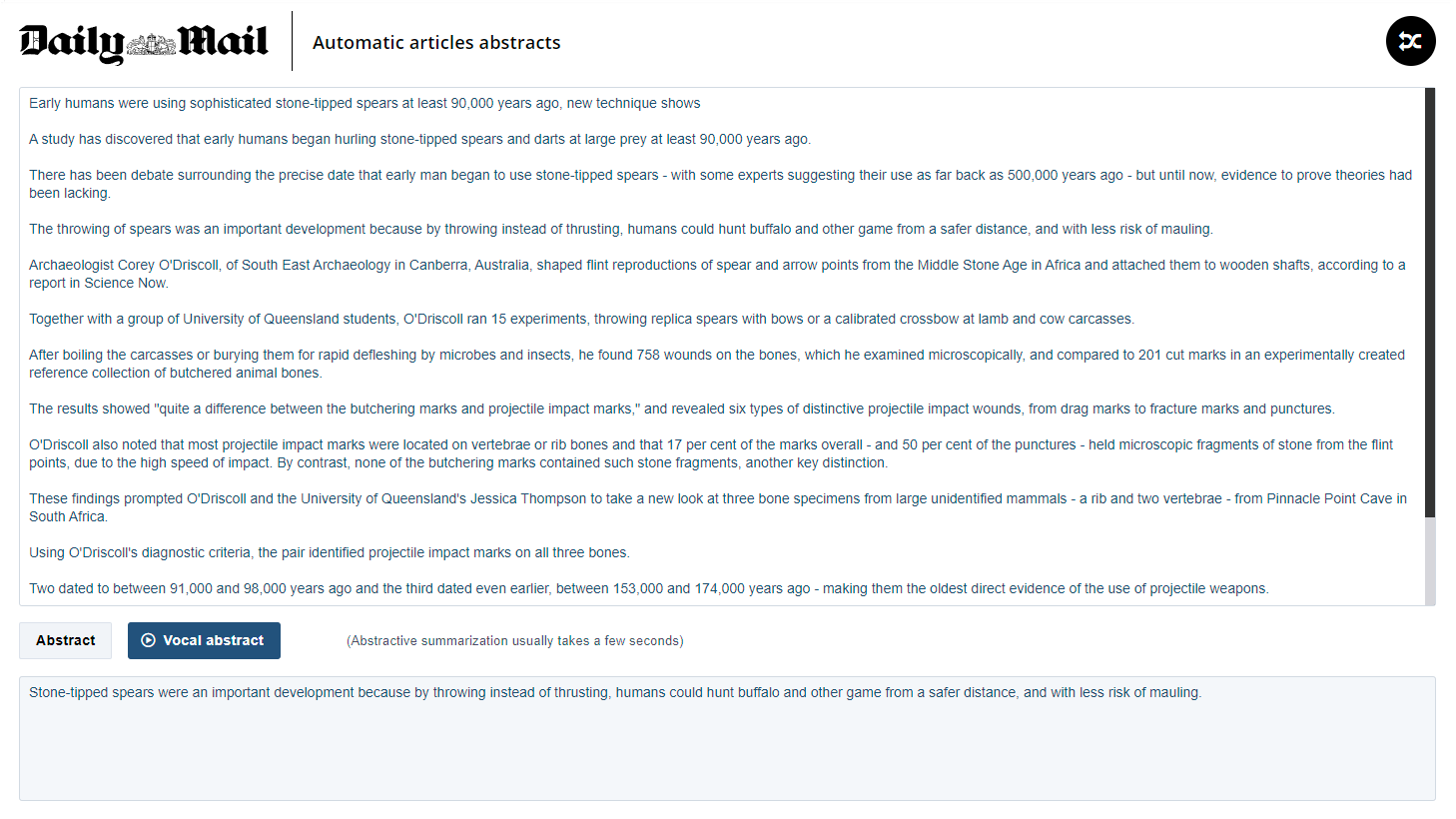
Daily Mail abstracts
Context - The Daily Mail is one of UK's most popular tabloids, covering topics from politics to entertainment, society, sports, celebs, etc., in styles not always "royal". This test case generates very short articles abstracts (text or vocal) that help catch up with the news in no time. On the same model, demos are available for US English, French, Spanish, Mexican Spanish, Colombian Spanish and Ecuadorian Spanish newspapers.
Documents type - This test case features widely available sources with and without HTML formatting. A hundred of random articles is provided for each newspaper, but any text can be pasted into the input area, including text copied directly from media websites.
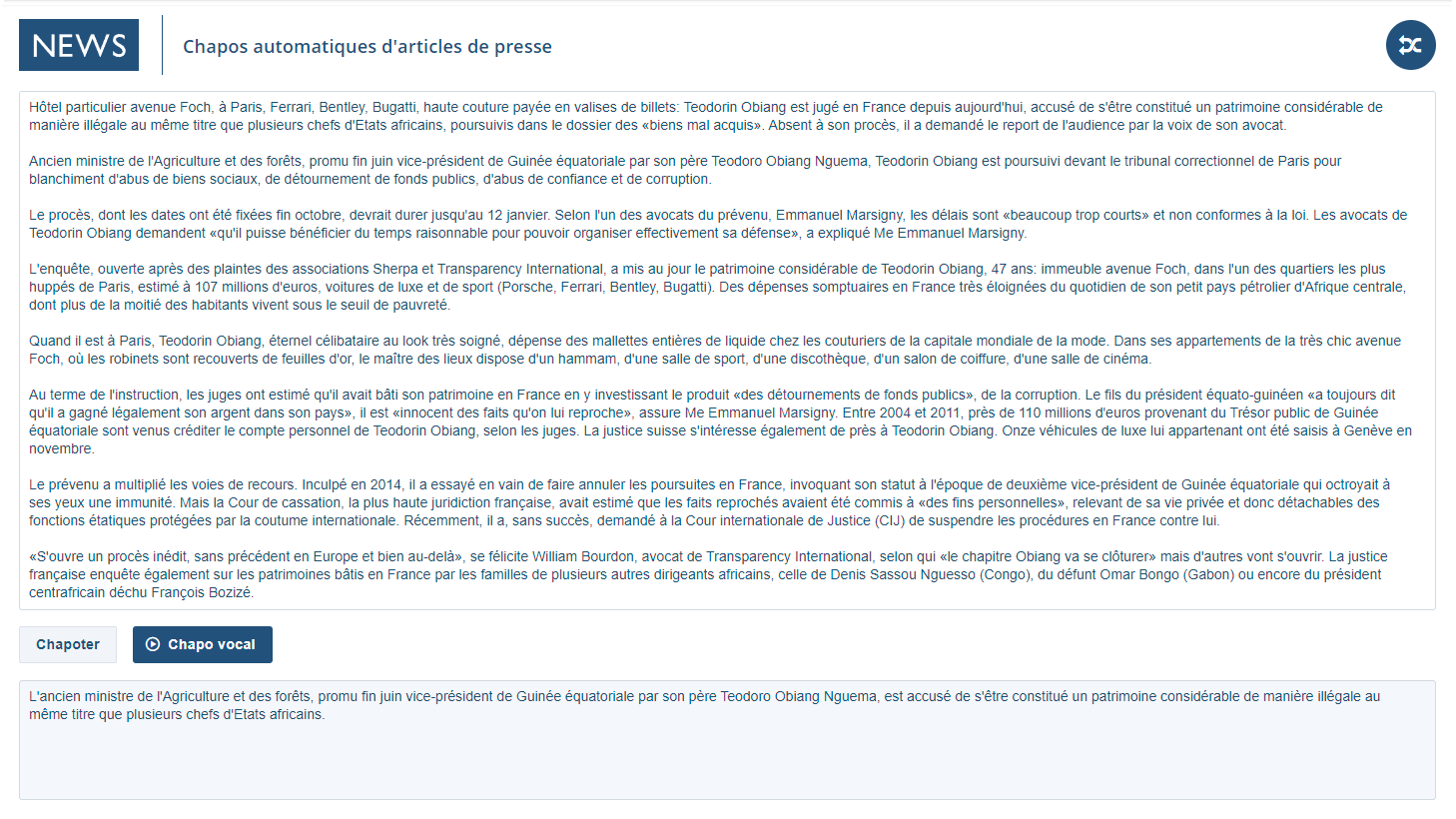
French Press headlines
Context - Compared to the Daily Mail abstracts demo presented above, this test case focuses on producing headlines ("chapos" in journalistic French) instead of abstracts. A headline is a paragraph that separates an article's title from its body. It is meant to tease or entice the reader into reading further, not to summarize the whole article. The task is therefore distinctive from pure summarization, requiring a different level of understanding.
Documents type - We used published articles from a variety of French newspapers and trade magazines. The articles cover a wide variety of topics, lengths, styles and vocabularies. As with other SensibleSummaries demos, content can be pasted and "headlined" in one click, with text and/or vocal results.
Your SensibleSummaries ROI
All documents summarization solutions are not created equal.
Here is why SensibleSummaries is the surest choice ROI-wise:

speedBenchmarks
ROUGE metrics [1]
(Generative summaries)
| English | French | Spanish | |
|---|---|---|---|
| Business | 35.99 / 14.08 / 29.11 | 33.91 / 12.59 / 27.48 | 36.82 / 14.40 / 29.46 |
| Press | 48.12 / 25.7 / 45.2 | 45.20 / 21.56 / 41.88 | 44.78 / 22.01 / 41.70 |
| Legal / Government | 59.67 / 41.58 / 47.59 | 63.01 / 40.22 / 60.57 | - |
In percentages. These are metrics, not scores. For summarization, 0% and 100% are not considered worst and best.
ROUGE, or Recall-Oriented Understudy for Gisting Evaluation, is a set of metrics for measuring technical aspects of automatic summaries.
In the table above, the first figure is the standardized ROUGE-1 value (F1 ratio). It represents the performance of capturing information in unigrams. Unigrams reflect the fluency of the summarized result.
The second figure is the standardized ROUGE-2 value (F1 ratio). It represents the conservation of bigrams (typically an entity and a specifier). This metric reflects the fidelity to the original wording for name chunks whose rephrasing would hinder the understanding of the summarized result.
The third figure is the standardized ROUGE-L, which represents the similarity between source and summary.
Please note that ROUGE values depend largely on the nature and average length of the source documents. That is why there's no concept of best (100%) or worst (0%) in ROUGE. In the table above, values also take into account LEXISTEMS' meaning-based approach, whereas ROUGE is known as a more syntactical than semantical instrument. We encourage you to compare them to the literature, keeping in mind the difference between extractive and generative (aka abstractive) summarization.
[1] November 2022 update.
handymanTechnical requirements
verifiedCertifications
Availability - Pricing - Support
Meet SensibleSummaries
Time is what you make of it.
In a one-to-one session or an interactive video call, see for yourself how SensibleSummaries will benefit your business...